TL;DR. #
-
I spent some dedicated time trying “vibe coding” (a.k.a. chat-orient programming) with Claude Code.
-
Despite being sceptical, I tried to go in with a positive, open mindset.
-
It's quite convincing at first.
- It seems to “understand” your problem.
- It seems to generate code “effortlessly”.
- The code looks somewhat plausible.
- It feels easy.
- They almost always comment the code.
- Sometimes, the comments and the code match.
-
But the more you look, the less impressive it is.
-
In fact, it's exactly like other chatbot output: it tends to have the right form, but often the wrong content.
-
To anthropomorphize Claude:
- Claude “cheats”, missing cases and using invalid heuristics.
- Claude is “lazy” (and not in the sense of Larry Wall's Three Virtues). It takes dangerous, invalid short-cuts.
- Claude is very “forgetful”.
- Claude's standard operating procedure for fixing tests seems to be to be to change the test results rather than fixing the code.
- Claude “blows smoke up your arse”, routinely apologising and saying you're right and have good ideas, but often then continuing down the wrong path.
- Claude is surprising terrible at obeying formatting instructions, even when it has Black and Ruff available (for Python).
- Claude is “self-congratulatory”, always claiming victory as soon as the tests pass (but not really in the way Kent Beck meant).
- Claude's code is full of baffling no-ops (code that has no effect, or no useful effect) and pointlessly redundant code.
- Claude appears not “know" about DRY (don't repeat yourself) or the Rule of Three.
- While all of Claude's failure modes are exhibited by people too, they are somehow stupider and, in many cases, mistakes it would be unusual for a human to make. As a result I think they are harder to spot.
-
I am confident I would have produced better code more quickly without Claude.
-
After spending all morning with Claude getting it to an apparently working state, with passing tests, I spent the afternoon building my confidence in it by (as it turned out) fixing code, fixing tests, and adding more tests.
-
At the end of the exercise, I feel less confident in the code than if I had written it (or another human had), even though I now have enough tests that I should feel confident. But nature of Claude's mistakes feels alien, and might require different kinds of tests.
-
I think about Kernighan's Law a lot.
Everyone knows that debugging is twice as hard as writing a program in the first place. So if you’re as clever as you can be when you write it, how will you ever debug it?
— Brian Kernighan, The Elements of Programming Style, B. W. Kernighan & P. J. Plaugher, McGraw-Hill, 1978.
-
The better developers I know who use Chatbots for programming say they use it to write boilerplate code and then check it carefully. This is fine, if they can pay enough attention, which I think is hard. But a lot of vibe coding is people getting bots to write code they don't really understand. That seems dangerous. (Perhaps vibe coding really does allow one person to the tehcnical debt normally accruing to a dozen.)
Obviously, that's all quite negative. Didn't it do anything good?
Ken Liu famously wrote:
It is not so much how well the dog dances, she thought, but that a dog is dancing at all.
— Ken Liu, The Hidden Girl and Other Stories, https://www.goodreads.com/work/quotes/71431737-the-hidden-girl-and-other-stories
My feeling about LLMs and Chatbots in general, and Coding bots like Claude Code specifically, is a bit like that. It is amazing that they can produce coherent, sometimes correct sentences, and plausible-looking, sometimes correct code at all; but it's a kind of trick. Just as chatbots don't produce answers to questions, but rather spit out sequences of words (tokens) that are statistically likely to be the sorts of words and sentences that might answer the questions, coding bots spit out sequences of program tokens and fragments that are statistically likely to be related to the coding questions you ask.
Another person I know who uses them (Laszlo Sranger of CQ4DS, who also blogs) says he values them only as a replacement for Stack Overflow, i.e.\ is, he asks them how to do very specific things and only believes the answers after verifying them. This may be a good, relatively safe use of them today.
Interlude: The Story of X #
I've recruited hundreds of developers, analysts, and data scientists over several decades, using a variety of interviewing approaches. One time, a few years ago (in the before times; BC; Before Chatbots) we needed to hire a couple of contractors as data engineers, on a fairly short-term basis. The work was not especially difficult, so all we really wanted to do was to find people to whom we could talk and who seemed to have at least a basic knowledge of Python and SQL. (If you have ever hired for technical positions, you will know that it is far from uncommon for people to apply for positions claiming to be experts in areas of which they have no discernable experience at all.) To save hassle, we had partially written code for a Python task and an SQL query, which I had in a large editor window, and we literally just wanted the candidates at add two or three lines to complete the task. They didn't need to type or compile, and the tasks were routine. We didn't care, within reason, how they solved them, which we told them. I think we interviewed five people. Two sailed through. Two really struggled with at least one of the tasks. And then there was the fifth, whom we'll call “X”.
We tackled the SQL first. X kept asking me to try obviously non-functional code and it became clear that he didn't really know SQL and his approach was to get us to run some very generic pseudo-code he suggested and to see what error message was produced. He would then iterate towards a solution that made the database happy. We should have abandoned the interview at that point, but we'd laid out that there were two parts, so we continued. At some point during the Python exercise X said something like “I can't stand your IDE: I'll type”. He fired up his own IDE, shared his own screen, and typed out all the code we'd provided. He then tried to (not very successfully) to solve the problem.
In retrospect, I think X might have been the first vibe coder. His whole approach was to try a keyword and see what the IDE suggested next, and when the IDE was happy to try running it and, again carefully read the error messages and try to fix problems that way.
One of the knocks against LLMs is that they are “just” fancy autocompleters. But if you take away the “just”, this is not so much a knock as a literal description. LLMs iteratively guess (predict/infer/choose) the next token, literally automatically completing what they are given. The chatbot interfaces condition this by preparing a more complex prompt and by using reinforcement learning with human evaluation to bias the outputs towards “better” ones, but it's still a kind of autocompletion. Vibe coding is the same, but for code. They tend to add quite detailed comments to the code, I suspect, because it's exactly well commented/well documented code from which they can most easily learn, and which is easiest to coerce into the right form for natural-language prompting and code output.
But X was not only an early vibe coder: he also did something Claude itself does: run the code, read the error messages, and try to fix the code using the error messages as a guide. X was both a vibe coder and a coding bot made flesh flesh.
Background #
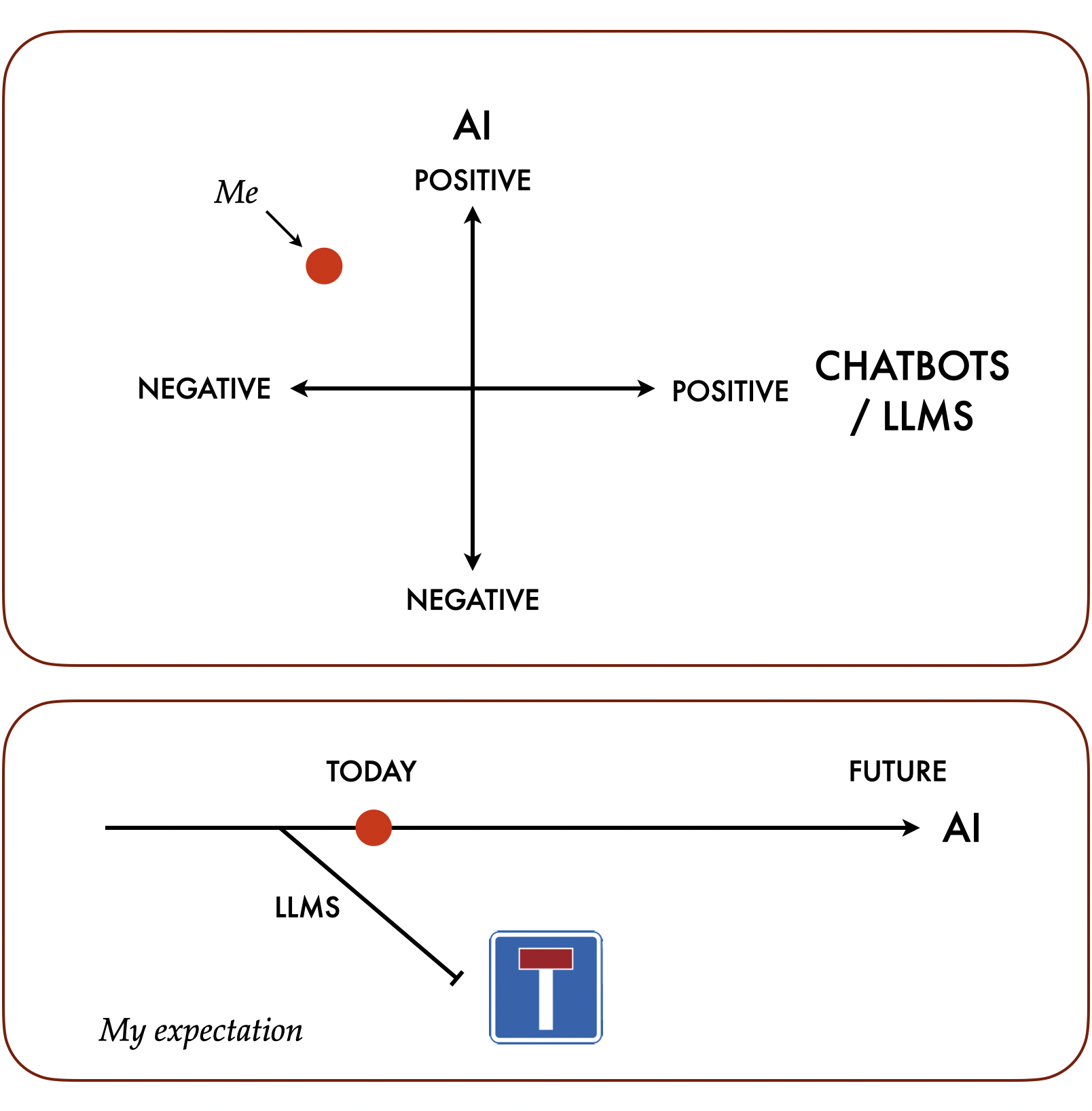
As the diagrams at the top of the post suggest, my basic position is that I pretty strongly believe in AI but am very sceptical about LLMs. Specifically, I have been a believer in Strong AI since my teenage years, which is to say I believe that machines can in principle—and almost certainly will end up being able to—do pretty much anything humans can do, and more, including having consciousness, self-awareness etc. Indeed, for me, as someone non-religious, humans are more-of-less an existence proof for strong AI, even though we are evolved rather than artificially engineered. I'm as impressed as anyone with things like the use of machine learning for medical image diagnosis, Alpha Zero for Go, Alpha Fold for protein folding, modern text to speech and handwriting recognition, among many other practical, almost boring uses of AI today.
I'm not really negative about LLMs per se: I think they are amazingly (as in, very surprisingly) powerful. But I think that if and when we do get to human-level or super-human intelligence, and perhaps sentience in machines, LLMs will not be a key part; they will be seen to have been a mis-step, a dead end from which we will have to backtrack. At least, that's what I think it most likely. If they do form part of superintelligent systems, I think their part will be that of mindless hypothesis generators, and intelligent supervisor systems will sift, sort, test, evaluate, accept and reject those hypotheses. That's really the role of the parts of the chatbots (and coding bots etc.) outside the LLM today. They augment the prompts, use reinforcement learning from humans to weight raw output, filter the inputs and the outputs, feed in context etc. They're just not very good at it. So what I am really negative about is today's chatbots, and the suggested uses for and hype around them and LLMs.
I don't really use LLMs, and for the reasons above, I am mostly sanguine about that. But I also realise I might be wrong, and don't particularly want to be left behind if I am. So despite my technical reservations (and some concerns about their environmental impact), I've been trying to engage with the seriously so that my scepticism is at least informed.
The two specific people who have most persuaded me that it would be foolish to discount vibe coding are Simon Willison and Steve Yegge. Simon is independent and has been super-enthusiastic about LLMs and Chatbots from the start, and blogs and talks endlessly about them, but I knew and respected his work before the advent of LLMs. He recently talked (typically enthusiastically) about them on the Half Stack Data Science podcast, saying (among many other things):
If your position is that this stuff makes no difference to programming as a career you just wrong. [...] it absolutely affects all of us in the career that we have chosen.
— Simon Willison, Half Stack Data Science Podcast, Series 4, Episode 2, 2025-03-21, c. t=27m50s.
I have been reading Steve Yegge for decades and have long regarded him as one fo the most thoughtful, wisest coders around. He now works at SourceGraph, which produces Cody, what he calls a Chat Oriented Programming system (CHOP), a term that predates “vibe coding” by several weeks, I think. You can watch him talking someone through some chat-oriented programming here. Although he is obviously not neutral, I tend to take Yegge pretty seriously, and he clearly thinks there's something to it. He has a pretty good track record on before-the-event predictions too, as Dan Luu points out.
Task and Experience #
After watching the Steve Yegge video, I resolved to try CHOP, but quickly lost my appetite after gaining the impression that it is really only available with an IDE such as VS Code. But I knew this was probably wrong, and a few weeks later heard about Claude code, which works in the terminal and soundded much more suitable for me. Claude probably has the best reputation as a coding bot anyway, so I installed that, which was fairly straightforward and went.
The first thing I did was spent a morning using it to fix a broken test in the Python tdda library I maintain. This was a fairly underwhelming experience, but did work, albeit slowly, and I learned how to use it.
This week, I thought I'd try a new code task. I had a parquet file with a numeric classification, 1–5, for every postal outcode in the UK. (The outcode is the first chunk of the postcode, often referred to as the postal district, which is correct for things like EH3, and G1. Some London outcodes include subdistricts like SW1A.) I wanted to summarize the classifications with a short kind of wildcard pattern for the postal sectors so that if G8, G9, G10, an G11 all had the same classification, theyu could be summarized as G8-11 etc. There was something similar for subdistricts, and if a whole postal area (the letters at the start of the postcode, like EH) has the same classification, it could just be EH. There was also a single 'UNKNOWN' pseudo-outcode, reperesenting null and bad postcodes, and that also had a category. It's not a very hard problem, but it's slightly fiddly and easy to get wrong, especially since I wanted contiguous district numbers to be grouped (like 8-11) rather than grouping G1, G10, G11 etc.
I won't go through everything that happened, but here are some of the things I encountered. (Obviously, I was prompting, and different prompts, among other things, would have changed the results.)
-
At a trivial level, Claude was over-eager, and would start coding before the specification was finished. I asked it to wait till I said "go", and it said it would, and I repeated this pattern throughout the session, but it often forgot and went off half-cock. Maybe it only forgot after it cleared its buffer (which it seemed to need to do really frequently, even though the code was tiny), I'm not sure. But it was like a wild horse, rearing to go.
-
Cheating
-
It was also surprisingly difficult to get it to format code as instructed (things like max line length 79, single quotes by default, no trailing whitespace, include a newline at the end of the file). Those things obviously don't matter, and could have been fixed at the end, but were a constant annoyance. I asked it if it could remember these intstructions, and it wrote configuration files for itself, black, and ruff, but it mostly ignored them,